| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Data Load
- tf.train.string_input_producer()
- I.MX6Q
- Machine learning
- Embedded System
- OpenCV
- IOT
- CNN
- cross compile
- tf.train.match_filenames_once()
- VGGnet
- porting
- tf.saver()
- Homomorphic Filter
- TensorFlow
- Machine Vision
- Raspberry Pi
- Facial expression recognition
- preprocessing
- Python
- ARM Processor
- deep-learning
- Today
- Total
Austin's_Lab
[Tensorflow] Facial expression recognition using adaptive VGGnet19 model(1) 본문
[Tensorflow] Facial expression recognition using adaptive VGGnet19 model(1)
Ausome_(Austin_is_Awesome) 2017. 7. 18. 12:25-Tensorflow 0.12.0사용 on Ubuntu 14.04-
4학년 1학기 Embedded System과 Pattern Recognition 수업에서 병행하여 진행한 프로젝트의 일환이다.
서버는 I.MX6Q 보드에서 촬영된 얼굴 영역 이미지를 전송받아, 화남, 슬픔, 기쁨, 평상 네 가지 감정 중 어떤 감정인 지 판단하여 결과를 보드에 돌려주어야 한다. 서버를 구축하는 과정은 총 5step으로 나뉜다.
1. 데이터 수집
2. 데이터 증식 및 전처리
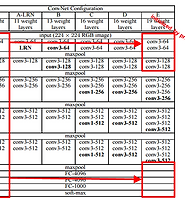
3. 학습 모델 선정 및 보완
4. 학습 및 테스트
5. 학습된 모델을 사용해 서버 프로그램 개발
1. 데이터 수집
표정 인식에 대한 연구가 이미 많이 진행돼 있어서 오픈된 표정 데이터는 많았지만, 우리가 원하는 표정만 추리고 보니 생각보다 쓸 수 있는 데이터가 너무 적었다. 그래서 표정인식 데이터 외에 오픈된 일반 얼굴 데이터를 받아서 일일이 표정별로 나누고, 구글 이미지 검색에서 나온 이미지 cropping, 연기자들의 표정 캡쳐, 얼굴인식에 대해 연구하셨던 타 연구실 교수님의 연구실 데이터, 친구들 및 팀원들 얼굴 등 얻을 수 있는 곳에서 최대한 얻었지만 그 중에서 또 애매한 표정, 저화질 이미지들을 거르고 나니 각 클래스 당 200~300 여 장밖에 남지 않았다. 우리가 사용한 오픈 데이터들은 CMU, Jaffe, Yale, Kohn-Kanade, IMFDB 등 대략 7여 군데에서 도움을 얻었으며 각 감정 별로 좀 과장된 표정들을 위주로 데이터를 수집했다.
2. 데이터 증식 및 전처리
앞서 수집한 데이터가 학습시키기엔 너무 적었기 때문에 Keras의 ImageDataGenerator 함수를 사용해 data augmentation을 진행했다. 정면 이미지만 학습시키기로 제한했으므로 반전은 horizontal flip만 사용하고, rotation 역시 기존에 약간 기울어진 얼굴들이 있기 때문에 10도 가량으로 제한을 두었다. shift range는 width, height 각각 0.01, shear와 zoom range는 0.1, 0.2로 설정을 하여 20개의 조합을 만들어내 학습데이터를 20배로 늘렸다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | import osfrom keras.preprocessing.image import ImageDataGenerator, img_to_array, load_imgfrom keras.import backend as KK.set_image_dim_ordering('th')path = '/the_path/where_the_data_sets/are_located/'### augmentation을 진행할 설정값 설정augmentation = ImageDataGenerator( rotation range = 30, width_shift_ragne = 0.01, height_shift_rnage = 0.01, shear_range = 0.1, zoom_range = 0.1, horizontal_flip = True, vertical_flip = False, fill_mode = 'nearest')i = 0directory = 'The_directory_of_each_class/'files = os.listdir(path+dir)for file in files : ### 이미지를 불러와서 numpy array (1, 3, 128, 128)로 reshaping 해준다. (batch_size, color_space, height, width) img = load_img(path+directory+file) x = img_to_array(img) x = x.reshape((1,) + x.shape) for batch in datagen.flow(x, batch_size=1, save_to_dir=path+'dir_to_save/', save_prefix='something%d'%i, save_format='jpeg'): i+=1 if i%20 == 0: break |
이렇게 2~300장의 학습 데이터는 4~5000장으로 늘어났다. 이제 전처리를 할 단계이다. 이미지마다 찍은 장소, 시간, 인종, 빛의 방향 등이 매우 다양했다. 사실 여러 방향에서 조명을 주고 찍은 데이터들도 많았는데, 어차피 빛을 제외한 모든 feature가 비슷한 상태에서 빛에 대한 값만 조금씩 다르다면 차라리 조명값을 normalize해버려서 특정 feature들이 과도하게 중복되는 것을 막는 것이 낫다고 생각했다. 이를 위해 Homomorphic filter로 조명을 제거하고 histogram equalization으로 대비를 최대화 시켜주었다.
2017/07/10 - [Machine Vision] - [Image processing] Homomorphic Filter 구현 in python
2017/07/12 - [Embedded System] - [Embedded System]얼굴 표정인식을 통해 사용자의 감정을 케어해주는 시스템 <- 결과 이미지는 여기 참조